Publications
Find more information on my Google Scholar profile.
2025
- Machine Intelligence Research
 A Survey on Personalized Content Synthesis with Diffusion ModelsXulu Zhang, Xiaoyong Wei, Wentao Hu, Jinlin Wu, Jiaxin Wu, Wengyu Zhang, Zhaoxiang Zhang, Zhen Lei, and Qing LiMachine Intelligence Research, Sep 2025
A Survey on Personalized Content Synthesis with Diffusion ModelsXulu Zhang, Xiaoyong Wei, Wentao Hu, Jinlin Wu, Jiaxin Wu, Wengyu Zhang, Zhaoxiang Zhang, Zhen Lei, and Qing LiMachine Intelligence Research, Sep 2025Recent advancements in diffusion models have significantly impacted content creation, leading to the emergence of personalized content synthesis (PCS). By utilizing a small set of user-provided examples featuring the same subject, PCS aims to tailor this subject to specific user-defined prompts. Over the past two years, more than 150 methods have been introduced in this area. However, existing surveys primarily focus on text-to-image generation, with few providing up-to-date summaries on PCS. This paper provides a comprehensive survey of PCS, introducing the general frameworks of PCS research, which can be categorized into test-time fine-tuning (TTF) and pre-trained adaptation (PTA) approaches. We analyze the strengths, limitations and key techniques of these methodologies. Additionally, we explore specialized tasks within the field, such as object, face and style personalization, while highlighting their unique challenges and innovations. Despite the promising progress, we also discuss ongoing challenges, including overfitting and the trade-off between subject fidelity and text alignment. Through this detailed overview and analysis, we propose future directions to further the development of PCS.
@article{zhang2025a, author = {Zhang, Xulu and Wei, Xiaoyong and Hu, Wentao and Wu, Jinlin and Wu, Jiaxin and Zhang, Wengyu and Zhang, Zhaoxiang and Lei, Zhen and Li, Qing}, title = {A Survey on Personalized Content Synthesis with Diffusion Models}, journal = {Machine Intelligence Research}, volume = {22}, number = {5}, pages = {817–848}, year = {2025}, month = sep, doi = {10.1007/s11633-025-1563-3}, eprint = {https://link.springer.com/content/pdf/10.1007/s11633-025-1563-3.pdf}, } - ACL
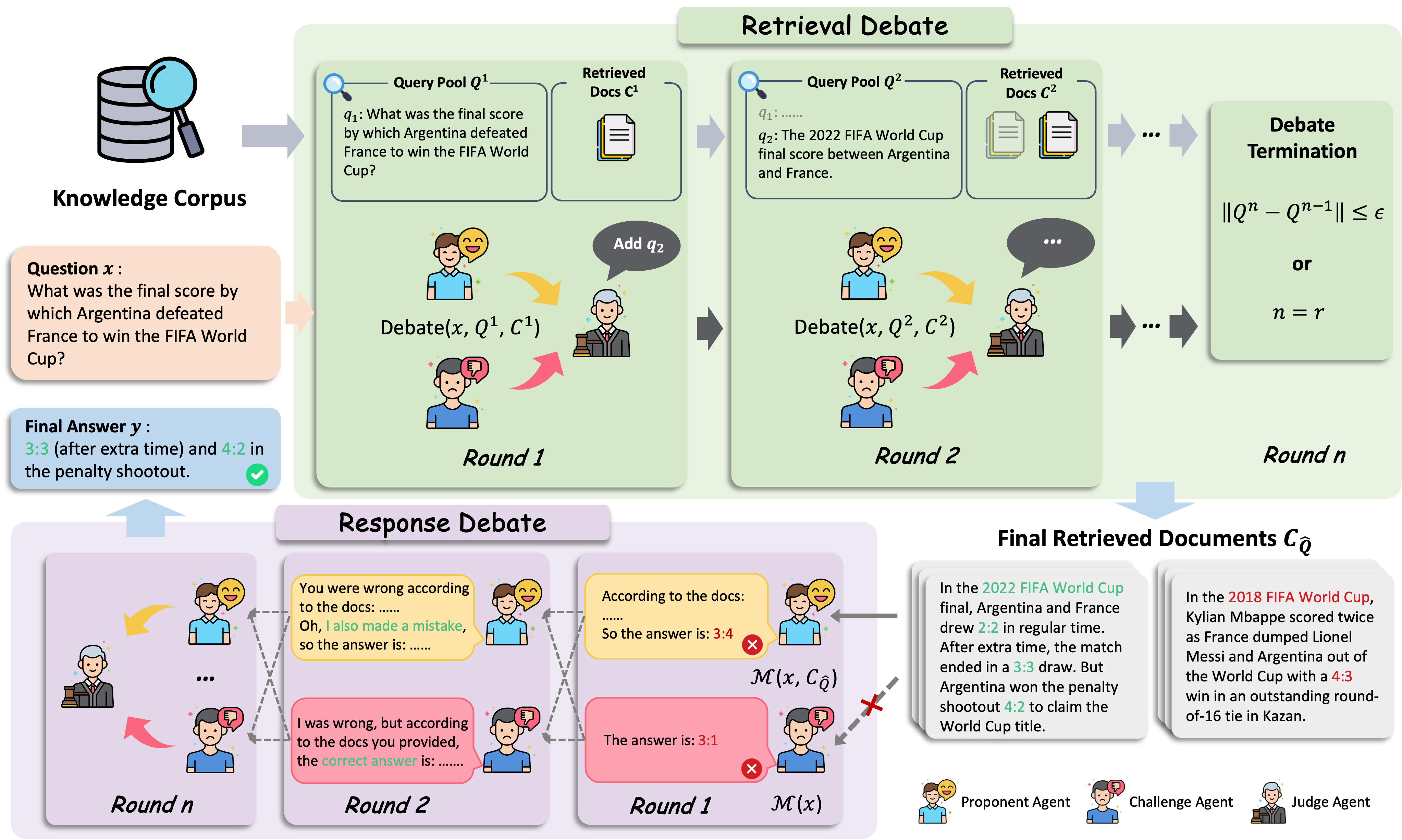 Removal of Hallucination on Hallucination: Debate-Augmented RAGWentao Hu, Wengyu Zhang, Yiyang Jiang, Chen Jason Zhang, Xiaoyong Wei, and Qing LiIn ACL 2025 Main, Sep 2025
Removal of Hallucination on Hallucination: Debate-Augmented RAGWentao Hu, Wengyu Zhang, Yiyang Jiang, Chen Jason Zhang, Xiaoyong Wei, and Qing LiIn ACL 2025 Main, Sep 2025Retrieval-Augmented Generation (RAG) enhances factual accuracy by integrating external knowledge, yet it introduces a critical issue: erroneous or biased retrieval can mislead generation, compounding hallucinations, a phenomenon we term Hallucination on Hallucination. To address this, we propose Debate Augmented RAG (DRAG), a training-free framework that integrates Multi-Agent Debate (MAD) mechanisms into both retrieval and generation stages. In retrieval, DRAG employs structured debates among proponents, opponents, and judges to refine retrieval quality and ensure factual reliability. In generation, DRAG introduces asymmetric information roles and adversarial debates, enhancing reasoning robustness and mitigating factual inconsistencies. Evaluations across multiple tasks demonstrate that DRAG improves retrieval reliability, reduces RAG-induced hallucinations, and significantly enhances overall factual accuracy. Our code is available at https://github.com/Huenao/Debate-Augmented-RAG.
@inproceedings{hu2025removal, title = {Removal of Hallucination on Hallucination: Debate-Augmented RAG}, author = {Hu, Wentao and Zhang, Wengyu and Jiang, Yiyang and Zhang, Chen Jason and Wei, Xiaoyong and Li, Qing}, booktitle = {ACL 2025 Main}, year = {2025}, } - Briefings in Bioinformatics
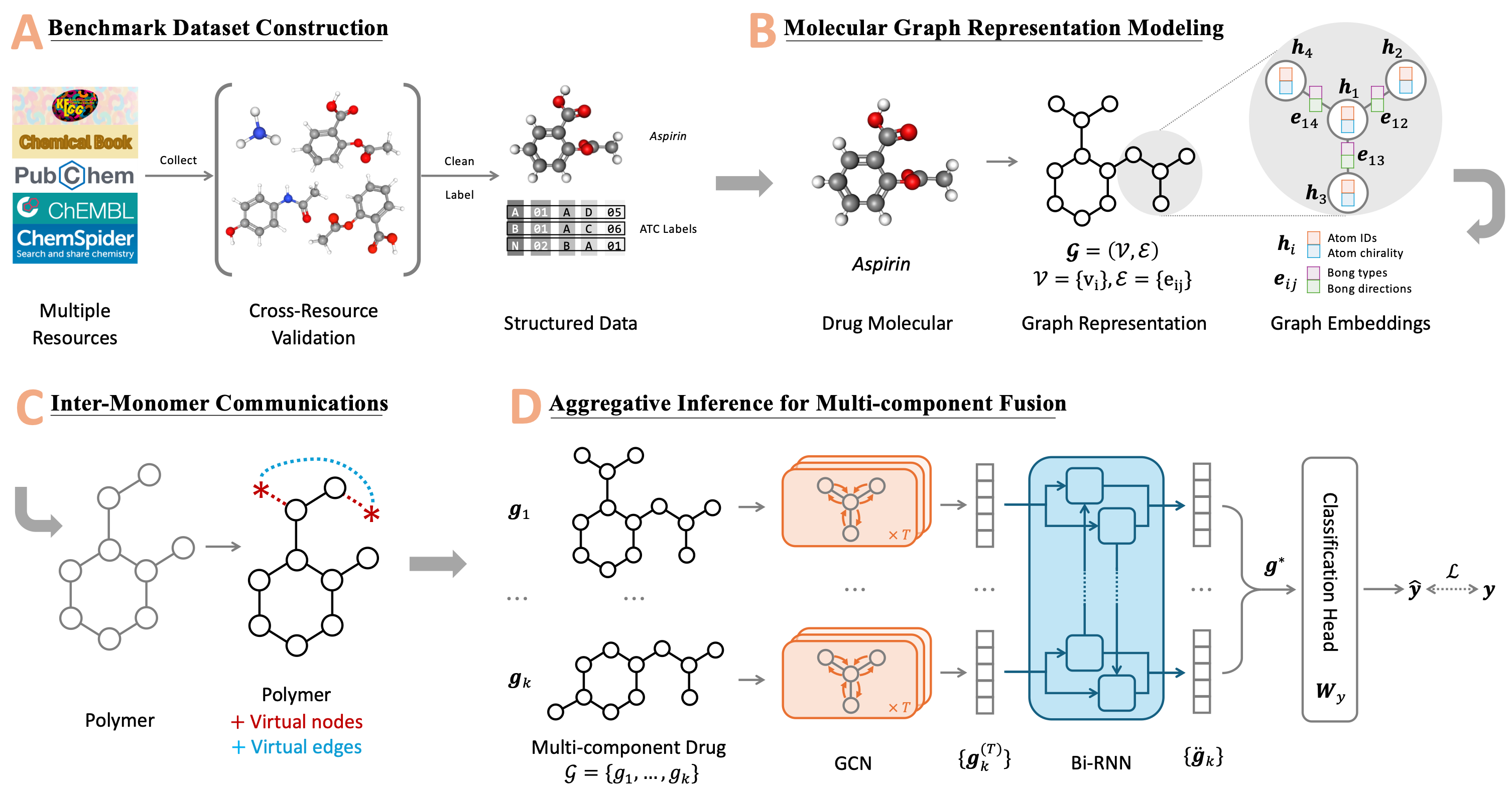 GraphATC: advancing multilevel and multi-label anatomical therapeutic chemical classification via atom-level graph learningWengyu Zhang, Qi Tian, Yi Cao, Wenqi Fan, Dongmei Jiang, Yaowei Wang, Qing Li, and Xiao-Yong WeiBriefings in Bioinformatics, Apr 2025
GraphATC: advancing multilevel and multi-label anatomical therapeutic chemical classification via atom-level graph learningWengyu Zhang, Qi Tian, Yi Cao, Wenqi Fan, Dongmei Jiang, Yaowei Wang, Qing Li, and Xiao-Yong WeiBriefings in Bioinformatics, Apr 2025The accurate categorization of compounds within the anatomical therapeutic chemical (ATC) system is fundamental for drug development and fundamental research. Although this area has garnered significant research focus for over a decade, the majority of prior studies have concentrated solely on the Level 1 labels defined by the World Health Organization (WHO), neglecting the labels of the remaining four levels. This narrow focus fails to address the true nature of the task as a multilevel, multi-label classification challenge. Moreover, existing benchmarks like Chen-2012 and ATC-SMILES have become outdated, lacking the incorporation of new drugs or updated properties of existing ones that have emerged in recent years and have been integrated into the WHO ATC system. To tackle these shortcomings, we present a comprehensive approach in this paper. Firstly, we systematically cleanse and enhance the drug dataset, expanding it to encompass all five levels through a rigorous cross-resource validation process involving KEGG, PubChem, ChEMBL, ChemSpider, and ChemicalBook. This effort culminates in the creation of a novel benchmark termed ATC-GRAPH. Secondly, we extend the classification task to encompass Level 2 and introduce graph-based learning techniques to provide more accurate representations of drug molecular structures. This approach not only facilitates the modeling of Polymers, Macromolecules, and Multi-Component drugs more precisely but also enhances the overall fidelity of the classification process. The efficacy of our proposed framework is validated through extensive experiments, establishing a new state-of-the-art methodology. To facilitate the replication of this study, we have made the benchmark dataset, source code, and web server openly accessible.
@article{zhang2025graphatc, author = {Zhang, Wengyu and Tian, Qi and Cao, Yi and Fan, Wenqi and Jiang, Dongmei and Wang, Yaowei and Li, Qing and Wei, Xiao-Yong}, title = {GraphATC: advancing multilevel and multi-label anatomical therapeutic chemical classification via atom-level graph learning}, journal = {Briefings in Bioinformatics}, volume = {26}, number = {2}, pages = {bbaf194}, year = {2025}, month = apr, issn = {1477-4054}, doi = {10.1093/bib/bbaf194}, eprint = {https://academic.oup.com/bib/article-pdf/26/2/bbaf194/63012495/bbaf194.pdf}, }



2024
- ACM MM (Oral)
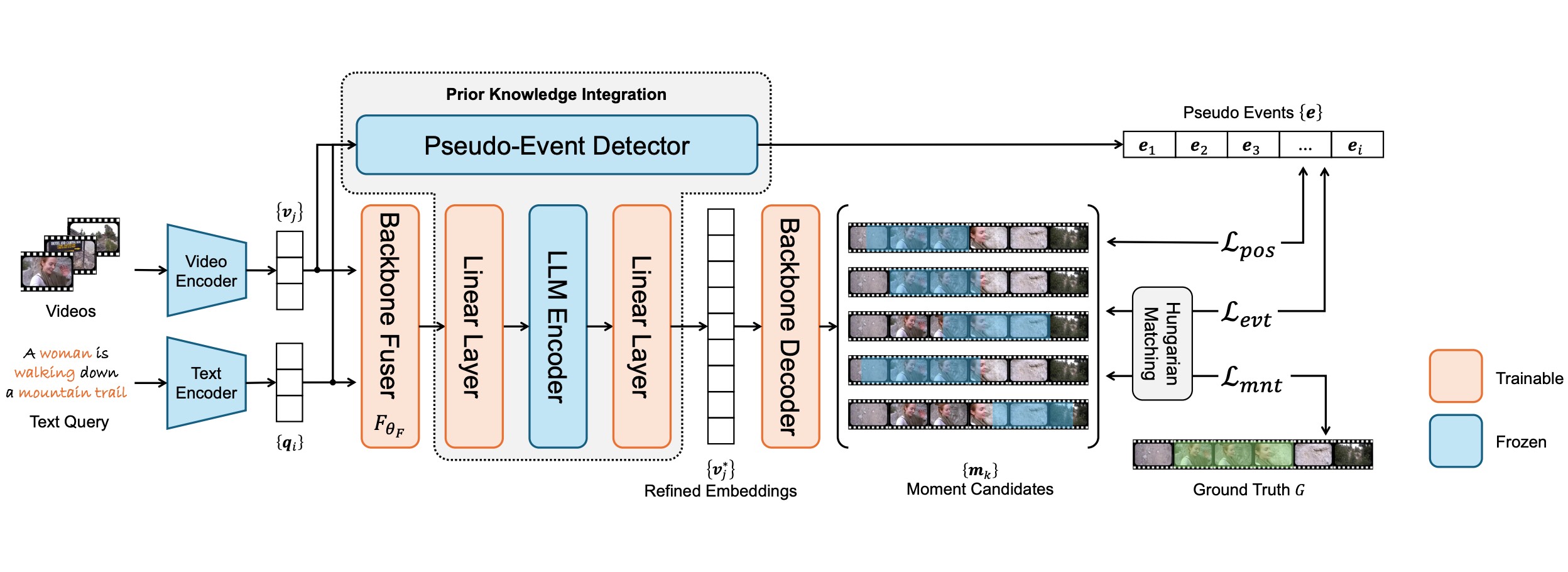 Prior Knowledge Integration via LLM Encoding and Pseudo Event Regulation for Video Moment RetrievalYiyang Jiang, Wengyu Zhang, Xulu Zhang, Xiaoyong Wei, Chang Wen Chen, and Qing LiIn ACM Multimedia 2024, Apr 2024
Prior Knowledge Integration via LLM Encoding and Pseudo Event Regulation for Video Moment RetrievalYiyang Jiang, Wengyu Zhang, Xulu Zhang, Xiaoyong Wei, Chang Wen Chen, and Qing LiIn ACM Multimedia 2024, Apr 2024In this paper, we investigate the feasibility of leveraging large language models (LLMs) for integrating general knowledge and incorporating pseudo-events as priors for temporal content distribution in video moment retrieval (VMR) models. The motivation behind this study arises from the limitations of using LLMs as decoders for generating discrete textual descriptions, which hinders their direct application to continuous outputs like salience scores and inter-frame embeddings that capture inter-frame relations. To overcome these limitations, we propose utilizing LLM encoders instead of decoders. Through a feasibility study, we demonstrate that LLM encoders effectively refine inter-concept relations in multimodal embeddings, even without being trained on textual embeddings. We also show that the refinement capability of LLM encoders can be transferred to other embeddings, such as BLIP and T5, as long as these embeddings exhibit similar inter-concept similarity patterns to CLIP embeddings. We present a general framework for integrating LLM encoders into existing VMR architectures, specifically within the fusion module. The LLM encoder’s ability to refine concept relation can help the model to achieve a balanced understanding of the foreground concepts (e.g., persons, faces) and background concepts (e.g., street, mountains) rather focusing only on the visually dominant foreground concepts. Additionally, we introduce the concept of pseudo-events, obtained through event detection techniques, to guide the prediction of moments within event boundaries instead of crossing them, which can effectively avoid the distractions from adjacent moments. The integration of semantic refinement using LLM encoders and pseudo-event regulation is designed as plug-in components that can be incorporated into existing VMR methods within the general framework. Through experimental validation, we demonstrate the effectiveness of our proposed methods by achieving state-of-the-art performance in VMR.
@inproceedings{jiang2024prior, title = {Prior Knowledge Integration via LLM Encoding and Pseudo Event Regulation for Video Moment Retrieval}, author = {Jiang, Yiyang and Zhang, Wengyu and Zhang, Xulu and Wei, Xiaoyong and Chen, Chang Wen and Li, Qing}, booktitle = {ACM Multimedia 2024}, year = {2024}, } - ACM MM (Oral, Best Paper Nomination)
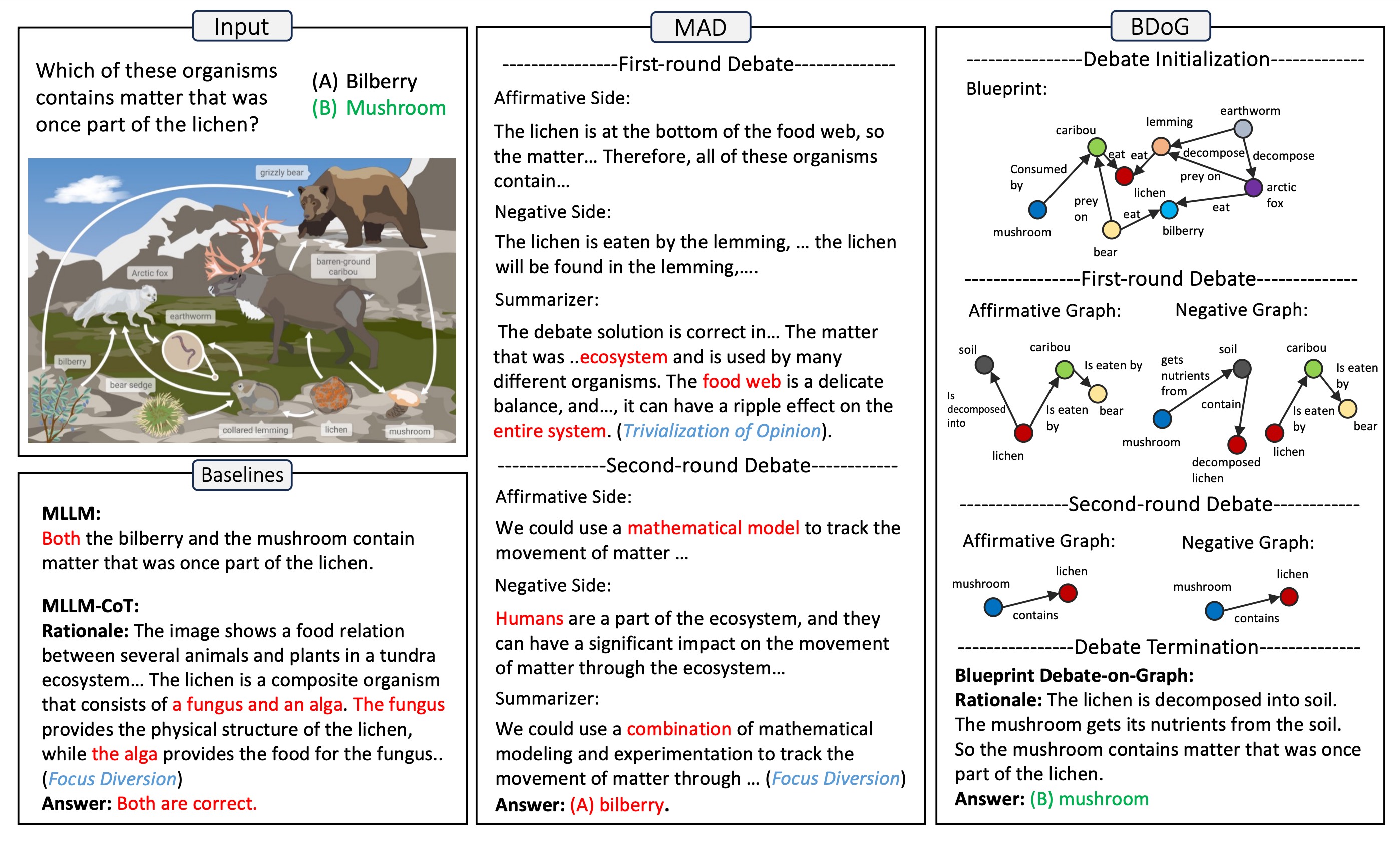 A Picture Is Worth a Graph: A Blueprint Debate Paradigm for Multimodal ReasoningChangmeng Zheng, DaYong Liang, Wengyu Zhang, Xiaoyong Wei, Tat-Seng Chua, and Qing LiIn ACM Multimedia 2024, Apr 2024
A Picture Is Worth a Graph: A Blueprint Debate Paradigm for Multimodal ReasoningChangmeng Zheng, DaYong Liang, Wengyu Zhang, Xiaoyong Wei, Tat-Seng Chua, and Qing LiIn ACM Multimedia 2024, Apr 2024This paper presents a pilot study aimed at introducing multi-agent debate into multimodal reasoning. The study addresses two key challenges: the trivialization of opinions resulting from excessive summarization and the diversion of focus caused by distractor concepts introduced from images. These challenges stem from the inductive (bottom-up) nature of existing debating schemes. To address the issue, we propose a deductive (top-down) debating approach called Blueprint Debate on Graphs (BDoG). In BDoG, debates are confined to a blueprint graph to prevent opinion trivialization through world-level summarization. Moreover, by storing evidence in branches within the graph, BDoG mitigates distractions caused by frequent but irrelevant concepts. Extensive experiments validate BDoG, achieving state-of-the-art results in Science QA and MMBench with significant improvements over previous methods.
@inproceedings{zheng2024a, title = {A Picture Is Worth a Graph: A Blueprint Debate Paradigm for Multimodal Reasoning}, author = {Zheng, Changmeng and Liang, DaYong and Zhang, Wengyu and Wei, Xiaoyong and Chua, Tat-Seng and Li, Qing}, booktitle = {ACM Multimedia 2024}, year = {2024}, } - ACM MM
 Generative Active Learning for Image Synthesis PersonalizationXulu Zhang, Wengyu Zhang, Xiaoyong Wei, Jinlin Wu, Zhaoxiang Zhang, Zhen Lei, and Qing LiIn ACM Multimedia 2024, Apr 2024
Generative Active Learning for Image Synthesis PersonalizationXulu Zhang, Wengyu Zhang, Xiaoyong Wei, Jinlin Wu, Zhaoxiang Zhang, Zhen Lei, and Qing LiIn ACM Multimedia 2024, Apr 2024This paper presents a pilot study that explores the application of active learning, traditionally studied in the context of discriminative models, to generative models. We specifically focus on image synthesis personalization tasks. The primary challenge in conducting active learning on generative models lies in the open-ended nature of querying, which differs from the closed form of querying in discriminative models that typically target a single concept. We introduce the concept of anchor directions to transform the querying process into a semi-open problem. We propose a direction-based uncertainty sampling strategy to enable generative active learning and tackle the exploitation-exploration dilemma. Extensive experiments are conducted to validate the effectiveness of our approach, demonstrating that an open-source model can achieve superior performance compared to closed-source models developed by large companies, such as Google’s StyleDrop. The source code is available at https://github.com/zhangxulu1996/GAL4Personalization
@inproceedings{zhang2024generative, title = {Generative Active Learning for Image Synthesis Personalization}, author = {Zhang, Xulu and Zhang, Wengyu and Wei, Xiaoyong and Wu, Jinlin and Zhang, Zhaoxiang and Lei, Zhen and Li, Qing}, booktitle = {ACM Multimedia 2024}, year = {2024}, } -
 Mean of Means: A 10-dollar Solution for Human Localization with Calibration-free and Unconstrained Camera SettingsTianyi Zhang, Wengyu Zhang, Xulu Zhang, Jiaxin Wu, Xiao-Yong Wei, Jiannong Cao, and Qing LiarXiv preprint arXiv:2407.20870, Apr 2024
Mean of Means: A 10-dollar Solution for Human Localization with Calibration-free and Unconstrained Camera SettingsTianyi Zhang, Wengyu Zhang, Xulu Zhang, Jiaxin Wu, Xiao-Yong Wei, Jiannong Cao, and Qing LiarXiv preprint arXiv:2407.20870, Apr 2024Accurate human localization is crucial for various applications, especially in the Metaverse era. Existing high precision solutions rely on expensive, tag-dependent hardware, while vision-based methods offer a cheaper, tag-free alternative. However, current vision solutions based on stereo vision face limitations due to rigid perspective transformation principles and error propagation in multi-stage SVD solvers. These solutions also require multiple high-resolution cameras with strict setup constraints. To address these limitations, we propose a probabilistic approach that considers all points on the human body as observations generated by a distribution centered around the body’s geometric center. This enables us to improve sampling significantly, increasing the number of samples for each point of interest from hundreds to billions. By modeling the relation between the means of the distributions of world coordinates and pixel coordinates, leveraging the Central Limit Theorem, we ensure normality and facilitate the learning process. Experimental results demonstrate human localization accuracy of 95% within a 0.3m range and nearly 100% accuracy within a 0.5m range, achieved at a low cost of only 10 USD using two web cameras with a resolution of 640x480 pixels.
@article{zhang2024mean, title = {Mean of Means: A 10-dollar Solution for Human Localization with Calibration-free and Unconstrained Camera Settings}, author = {Zhang, Tianyi and Zhang, Wengyu and Zhang, Xulu and Wu, Jiaxin and Wei, Xiao-Yong and Cao, Jiannong and Li, Qing}, journal = {arXiv preprint arXiv:2407.20870}, year = {2024}, }



