Publications
Find more information on my Google Scholar profile.
2024
- ACM MM
 Generative Active Learning for Image Synthesis PersonalizationXulu Zhang, Wengyu Zhang, Xiaoyong Wei, Jinlin Wu, Zhaoxiang Zhang, Zhen Lei, and Qing LiIn ACM Multimedia 2024, 2024
Generative Active Learning for Image Synthesis PersonalizationXulu Zhang, Wengyu Zhang, Xiaoyong Wei, Jinlin Wu, Zhaoxiang Zhang, Zhen Lei, and Qing LiIn ACM Multimedia 2024, 2024This paper presents a pilot study that explores the application of active learning, traditionally studied in the context of discriminative models, to generative models. We specifically focus on image synthesis personalization tasks. The primary challenge in conducting active learning on generative models lies in the open-ended nature of querying, which differs from the closed form of querying in discriminative models that typically target a single concept. We introduce the concept of anchor directions to transform the querying process into a semi-open problem. We propose a direction-based uncertainty sampling strategy to enable generative active learning and tackle the exploitation-exploration dilemma. Extensive experiments are conducted to validate the effectiveness of our approach, demonstrating that an open-source model can achieve superior performance compared to closed-source models developed by large companies, such as Google’s StyleDrop. The source code is available at https://github.com/zhangxulu1996/GAL4Personalization
@inproceedings{zhang2024generative, title = {Generative Active Learning for Image Synthesis Personalization}, author = {Zhang, Xulu and Zhang, Wengyu and Wei, Xiaoyong and Wu, Jinlin and Zhang, Zhaoxiang and Lei, Zhen and Li, Qing}, booktitle = {ACM Multimedia 2024}, year = {2024}, } - ACM MM
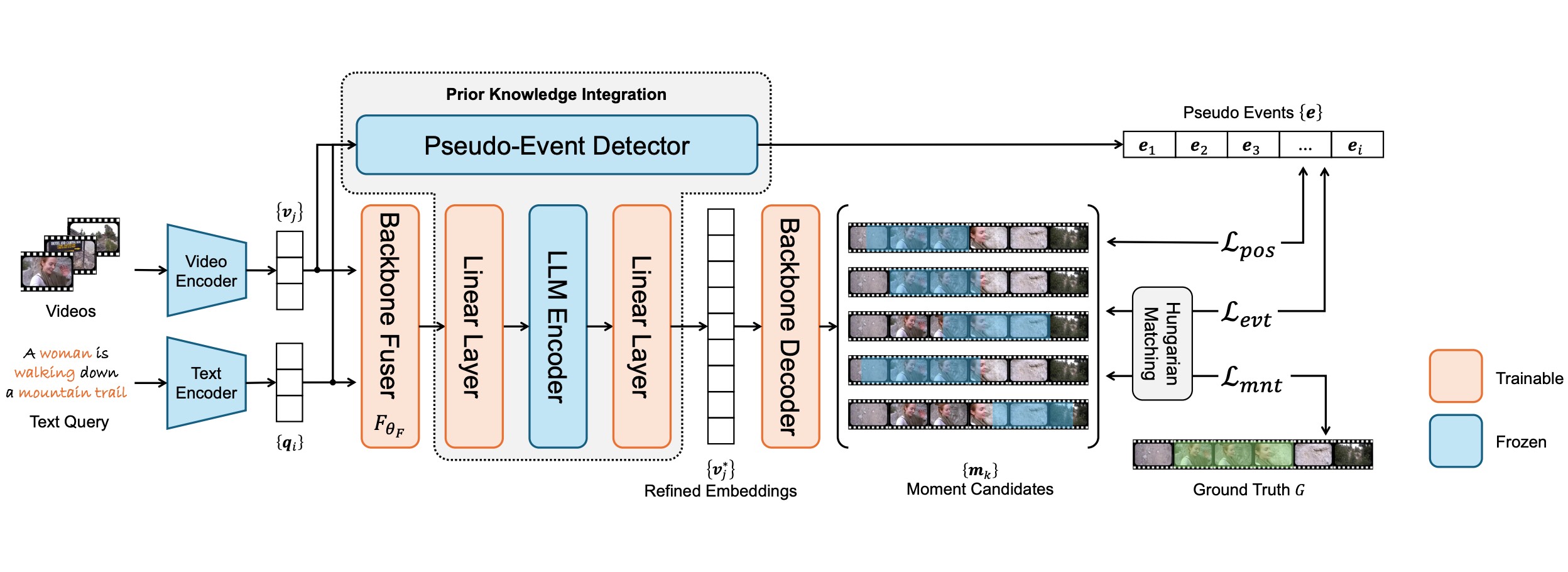 Prior Knowledge Integration via LLM Encoding and Pseudo Event Regulation for Video Moment RetrievalYiyang Jiang, Wengyu Zhang, Xulu Zhang, Xiaoyong Wei, Chang Wen Chen, and Qing LiIn ACM Multimedia 2024, 2024
Prior Knowledge Integration via LLM Encoding and Pseudo Event Regulation for Video Moment RetrievalYiyang Jiang, Wengyu Zhang, Xulu Zhang, Xiaoyong Wei, Chang Wen Chen, and Qing LiIn ACM Multimedia 2024, 2024In this paper, we investigate the feasibility of leveraging large language models (LLMs) for integrating general knowledge and incorporating pseudo-events as priors for temporal content distribution in video moment retrieval (VMR) models. The motivation behind this study arises from the limitations of using LLMs as decoders for generating discrete textual descriptions, which hinders their direct application to continuous outputs like salience scores and inter-frame embeddings that capture inter-frame relations. To overcome these limitations, we propose utilizing LLM encoders instead of decoders. Through a feasibility study, we demonstrate that LLM encoders effectively refine inter-concept relations in multimodal embeddings, even without being trained on textual embeddings. We also show that the refinement capability of LLM encoders can be transferred to other embeddings, such as BLIP and T5, as long as these embeddings exhibit similar inter-concept similarity patterns to CLIP embeddings. We present a general framework for integrating LLM encoders into existing VMR architectures, specifically within the fusion module. The LLM encoder’s ability to refine concept relation can help the model to achieve a balanced understanding of the foreground concepts (e.g., persons, faces) and background concepts (e.g., street, mountains) rather focusing only on the visually dominant foreground concepts. Additionally, we introduce the concept of pseudo-events, obtained through event detection techniques, to guide the prediction of moments within event boundaries instead of crossing them, which can effectively avoid the distractions from adjacent moments. The integration of semantic refinement using LLM encoders and pseudo-event regulation is designed as plug-in components that can be incorporated into existing VMR methods within the general framework. Through experimental validation, we demonstrate the effectiveness of our proposed methods by achieving state-of-the-art performance in VMR.
@inproceedings{jiang2024prior, title = {Prior Knowledge Integration via LLM Encoding and Pseudo Event Regulation for Video Moment Retrieval}, author = {Jiang, Yiyang and Zhang, Wengyu and Zhang, Xulu and Wei, Xiaoyong and Chen, Chang Wen and Li, Qing}, booktitle = {ACM Multimedia 2024}, year = {2024}, } - ACM MM
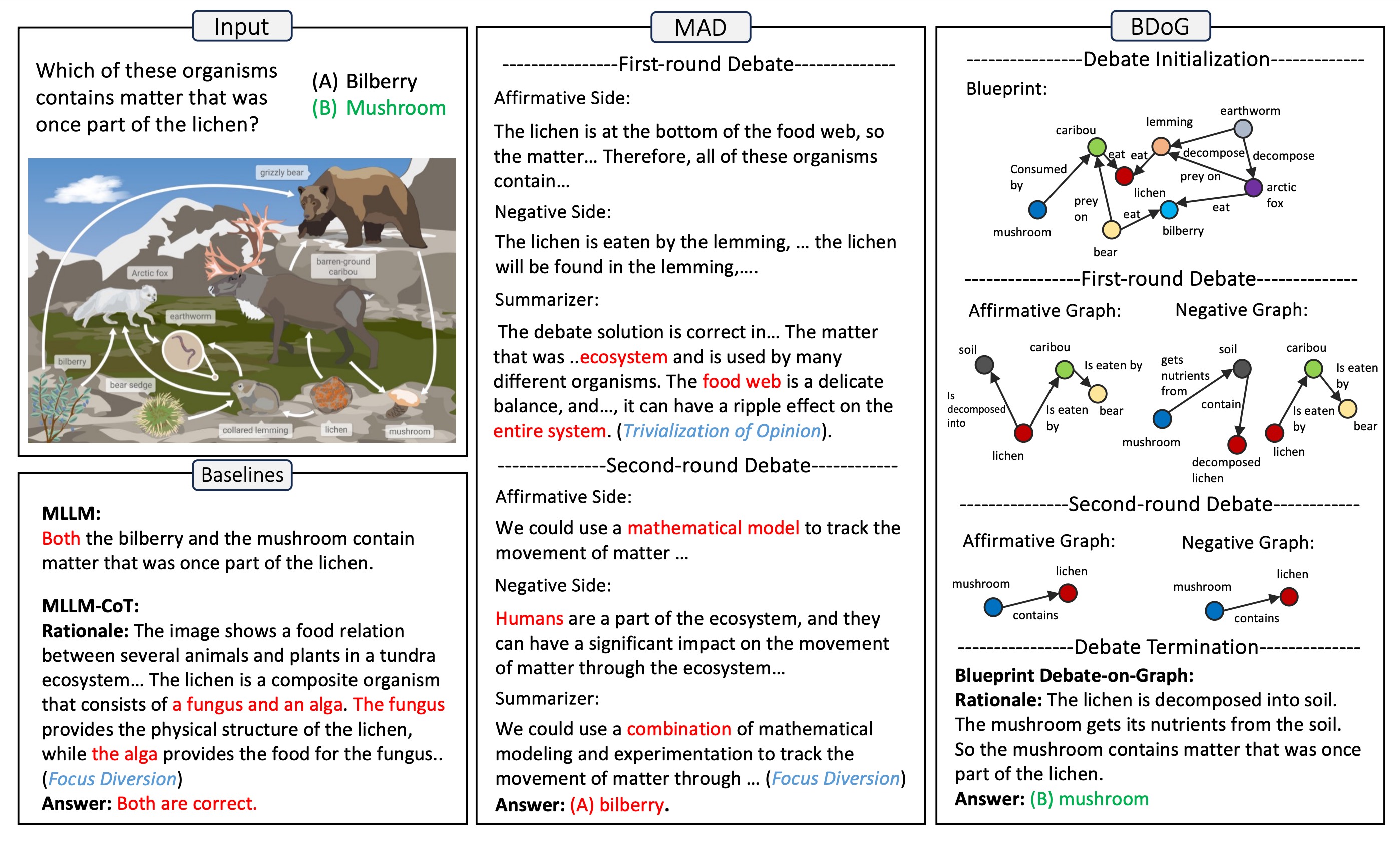 A Picture Is Worth a Graph: A Blueprint Debate Paradigm for Multimodal ReasoningChangmeng Zheng, DaYong Liang, Wengyu Zhang, Xiaoyong Wei, Tat-Seng Chua, and Qing LiIn ACM Multimedia 2024, 2024
A Picture Is Worth a Graph: A Blueprint Debate Paradigm for Multimodal ReasoningChangmeng Zheng, DaYong Liang, Wengyu Zhang, Xiaoyong Wei, Tat-Seng Chua, and Qing LiIn ACM Multimedia 2024, 2024This paper presents a pilot study aimed at introducing multi-agent debate into multimodal reasoning. The study addresses two key challenges: the trivialization of opinions resulting from excessive summarization and the diversion of focus caused by distractor concepts introduced from images. These challenges stem from the inductive (bottom-up) nature of existing debating schemes. To address the issue, we propose a deductive (top-down) debating approach called Blueprint Debate on Graphs (BDoG). In BDoG, debates are confined to a blueprint graph to prevent opinion trivialization through world-level summarization. Moreover, by storing evidence in branches within the graph, BDoG mitigates distractions caused by frequent but irrelevant concepts. Extensive experiments validate BDoG, achieving state-of-the-art results in Science QA and MMBench with significant improvements over previous methods.
@inproceedings{zheng2024a, title = {A Picture Is Worth a Graph: A Blueprint Debate Paradigm for Multimodal Reasoning}, author = {Zheng, Changmeng and Liang, DaYong and Zhang, Wengyu and Wei, Xiaoyong and Chua, Tat-Seng and Li, Qing}, booktitle = {ACM Multimedia 2024}, year = {2024}, }


